幫助:使用Python編輯

- 本文用於介紹萌娘百科中一些特定功能的操作方法;
- 本文僅是一篇論述,不屬於方針或指引。如果本指南與相關方針或指引發生衝突或存在不一致的情況,請以方針或指引的條文為準。
這個指南會簡單介紹一下如何使用 Python 創建一個維護 wiki 的自動程序/機器人(bot),它可用於在 wiki 上面進行大量編輯或者刪除等維護操作。使用它的好處在於,只要您編寫過 Python程序,就可以輕鬆上手。
注意:閱讀以下內容,我們假定您擁有 Python 和命令行的基本知識。欲學習 Python,請前往官方文檔等其他站點。
配置
安裝Python
- 使用Windows 10、11和Mac的用戶可以直接下載最新版:https://www.python.org/downloads/
- 使用Windows 7的用戶能下載的最新版是Python 3.8:https://www.python.org/downloads/release/python-3810/
配置Python
Pywikibot是目前最常用的wiki編輯Python庫。除此之外,我們還會用到wikitextparser和requests。只需在命令行[注 1]中輸入
python3 -m pip install requests python3 -m pip install wikitextparser
即可。注意:由於部分操作系統同時包括Python2和Python3,因此推薦在命令中使用python3而不是python。但如果python3命令無法被識別,請使用python命令。
創造初始工程文件夾
從官網下載初始文件「core_stable.zip」,將其解壓。
解壓後會出現一個叫「core_stable」的文件夾,在文件夾中創建一個名為user-config.py的文件[注 2]。文件的內容為:
mylang = 'mgp'
family_files['mgp'] = 'https://zh.moegirl.org.cn/api.php'
family = 'mgp'
# 这里使用您自己的用户名
usernames['mgp']['*'] = '用户名'
password_file = "user-password.py"
然後,創建一個名為user-password.py的文件存儲用戶名和密碼。這裡的賬號必須是自動確認使用者,否則會因為驗證碼編輯失敗。
如果沒有創建bot賬號(見下文),文件內容為:
# 强烈不推荐这种登录方式:将不加密的密码存储在文件中是很大的安全隐患。
('mgp', 'mgp', '用户名', '密码')
如果已有bot賬號,文件內容為:
('mgp', 'mgp', '用户名', BotPassword('bot用户名', 'bot密码'))
因為pywikibot目前的登錄邏輯和本站對部分API的限制。請將core_stable/pywikibot/site/_apisite.py文件APISite類的get_token()方法中
if not types or load_all is not False:
pdata = self._paraminfo.parameter('query+tokens', 'type')
assert pdata is not None
types = pdata['type']
部分代碼替換為:
if not types or load_all is not False:
if self.logged_in():
pdata = self._paraminfo.parameter('query+tokens', 'type')
assert pdata is not None
types = pdata['type']
else:
types = ['login']
接下來,在控制台中使用cd命令進入「core_stable」文件夾,並執行以下命令[注 3]
python3 pwb.py login
登錄,此時會出現數行文字,最後一行應為提示登錄成功[注 4]。
Logged in on mgp:mgp as 用户名.
創建您的 bot 賬號(可選)
- 一般來說,我們不希望您使用自己的主要賬號運行自動程序,這不僅不合理,而且難以維護和監管,因此我們建議您另外註冊一個賬號作為 bot 賬號。
- 然後,您還可以為您的 bot 賬號申請一個 bot 用戶組,明確表示這是一個由他人操作自動程序進行編輯的子賬號,並且可以在最近更改中隱藏批量操作以防止擾亂社區巡查工作。您可以在萌娘百科:機器人#申請與授權了解相關信息。
- 最後,這一點相當關鍵:前往您 wiki 的 Special:BotPasswords 頁面,為您的 bot 賬號創建一個機器人密碼,按提示操作,並保存最後得到的密鑰,您之後會用到它。
編輯示例1: Hello World
在解壓的pywikibot文件夾中新建一個名為main.py的文件(與config.py處於同一個文件夾)。文件的內容為:
# 导入pywikibot
import pywikibot as pwb
# 获取名为Help:沙盒的页面
page = pwb.Page(pwb.Site(), "Help:沙盒")
# 给页面已有的内容添加Hello World
page.text += "Hello World"
# 可选:查看更改后的wikitext文本
print(page.text)
# 保存页面,编辑摘要为"测试pywikibot"
page.save(summary="测试pywikibot")
在控制台輸入python3 main.py運行機器人,稍等片刻後,輸出應為
...(页面已有内容) Hello World Page [[Help:沙盒]] saved
前往萌百,會發現這次修改已經在沙盒中生效。
編輯示例2:刪除模板參數
有一天,萌百的維護組給全體編輯們布置了一個艱巨的任務:因為{{YoutubeCount}}廢棄了fallback參數,所以每一個使用YoutubeCount模板的頁面都要被修改。例如
{{YoutubeCount|id=0KK5vQlCVYo|fallback=2968013}}
應改為
{{YoutubeCount|id=0KK5vQlCVYo}}
維護組已經給出了需要修改的條目的列表,但是除了少數想刷編輯的用戶外,沒有人願意幹這種毫無技術含量的體力活,刪除參數的事情因而進展緩慢[注 5]。這時,聰明的你突然想到可以用Python完成批量刪除參數,因此寫出了以下代碼用來測試。
# 导入pywikibot和wikitextparser
import pywikibot as pwb
import wikitextparser as wtp
# 获取一个页面,用页面名代替沙盒
page = pwb.Page(pwb.Site(), "Help:沙盒")
# 使用wikitextparser处理页面
parsed = wtp.parse(page.text)
# 遍历页面中的每一个模板
for t in parsed.templates:
# 如果模板是YoutubeCount,则删除fallback参数
if t.name == 'YoutubeCount':
t.del_arg("fallback")
# 用转换后的wikitext替换已有的wikitext
page.text = str(parsed)
# 保存页面并标记为小编辑(如果没有做出任何更改,会提示保存成功,但是页面不会有任何变化)
page.save(summary="删除fallback参数", minor=True)
接下來,只要讀取需要更改的條目列表,然後對每個條目重複以上步驟即可。
除了用於刪除參數的del_arg,wikitextparser還提供了用於獲取模板參數的get_arg和用於添加、修改參數的set_arg,以及更多功能。詳情見API文檔和下一個示例。
編輯示例3:再生機器人
假如有這樣一個模板[注 6]:
{{VOCALOID_Songbox
|乱七八糟的参数
|yt_id = 0KK5vQlCVYo
|其他资料 = 于2014年10月5日投稿至niconico,再生数为{{NiconicoCount|id=sm24626484}}<br>同日投稿至YouTube,再生数为1,993,000+
}}
突然,我們得知{{YoutubeCount}}可以自動獲取YouTube視頻的播放量,因此原有的"1,993,000+"可以被替換為{{YoutubeCount|id=0KK5vQlCVYo}}。因為需要修改的頁面過多,所以需要機器人輔助編輯。
程序的大概思路是:
- 獲取所有VOCALOID條目。對於每一個條目,做以下的事情:
- 獲取頁面的wikitext代碼。
- 因為一個條目可能有多個{{VOCALOID_Songbox}},如表里,所以應該選擇wikitext中的一個模板進行編輯。
- 找到該模板中YouTube視頻的id,也就是參數「yt_id」對應的值。
- 找到播放量曾經的位置,也就是「其他資料」參數中的「1,993,000+」。
- 將「1,993,000+」替換為
{{YoutubeCount|id=0KK5vQlCVYo}}。 - 保存更改。
雖然可以通過正則匹配查找模板和參數,但是有更簡單的方法:使用wikitextparser。以下是編輯一個條目的代碼:
# 导入pywikibot和wikitextparser
import pywikibot as pwb
import wikitextparser as wtp
# 使用正则查找播放量
import re
# 获取一个页面,用页面名代替沙盒
page = pwb.Page(pwb.Site(), "Help:沙盒")
# 使用wikitextparser处理页面
parsed = wtp.parse(page.text)
# 记录页面有无变化
changed = False
# 遍历页面中的每一个模板,并找出所有的VOCALOID_Songbox。
song_boxes = []
for t in parsed.templates:
# 添加所有名字是VOCALOID_Songbox的模板
if "VOCALOID_Songbox" == t.name.strip():
song_boxes.append(t)
# 遍历所有songbox
for t in song_boxes:
# 获取YouTube视频的id和“其他资料”参数的内容
# 使用get_arg返回的是一个对象,包含name(参数名)和value(参数值)
# 不存在的参数则会返回None
yt_id = t.get_arg("yt_id")
other_info = t.get_arg("其他资料")
# 如果两者中的任意一个不存在,则跳过该模板(有可能YouTube无投稿)
if yt_id is None or other_info is None:
continue
# 可选:此时的yt_id.value就是YouTube视频的id
print(yt_id.value.strip())
# 使用正则查找播放量,仅为简单例子,实际使用时的正则会更复杂。
match = re.search("[0-9][0-9,]+[+]", other_info.value)
# 如果找不到播放量,跳过
if match is None:
continue
# 找出数字播放量开始和结束的位置
start = match.start()
end = match.end()
# 新模板。使用strip去除YouTube视频id中的空格。
template = "{{YoutubeCount|id=" + yt_id.value.strip() + "}}"
# 修改“其他信息”的值,将原有内容中的数字部分替换为模板
other_info.value = other_info.value[:start] + template + other_info.value[end:]
# 标记页面已修改
changed = True
# 如果页面被修改过,保存更改,否则告知用户条目没有被修改
if changed:
# 将修改后的wikitext对象转换为字符串,并用它覆盖页面原有的内容
page.text = str(parsed)
# 保存编辑
# minor: 是否是小编辑
# botflag: 机器人flag,如果没有机器人或机器用户权限,则没有任何影响。
# tags: 加入编辑标签,用管道符|分割多个标签。Automation tool指的是“由半自动化脚本或半自动化工具执行的操作”。test指的是测试。
# watch: 是否添加至监视列表,"nochange"指的是不改变监视列表
# 可自行在萌百的[https://zh.moegirl.org.cn/api.php api页面]中了解对应的意义
page.save(summary="测试", minor=True, botflag=True, watch="nochange", tags="Automation tool|test")
else:
print("没有对页面作出任何修改。")
能夠轉換一個條目後,接下來只需要獲取所有分類為「使用VOCALOID的歌曲」的條目,然後轉換每個條目。貼心的官方已經寫好了代碼,只要會調用即可。
需要注意的是,代碼示例中展示了如何避免常見錯誤,例如參數不存在。但是也跳過了很多可能遇到的坑,比如模板名的對比是會被首字母是否大寫影響的,因此很可能出現「lj」不等於「Lj」的狀況。
小提示
選用編輯器
如果您還在使用類似記事本的編輯器,很快就會發現諸如縮進、括號配對、拼寫錯誤等問題難以發現。因為記事本的功能過於貧乏,所以建議您選用更強大的工具編寫代碼:
- Sublime Text是一個輕量級的文本編輯器。如果您只是想使用最基本的功能(如文本高亮)或你的電腦配置較差,Sublime Text可以在占用較少資源的前提下滿足您的需求。
- Visual Studio Code與Sublime Text類似,但是功能更多,且支持大量插件滿足您不同的需求,是很受歡迎的選擇。
- PyCharm分為
社區版( )和專業版( )。收費版可以試用。PyCharm集成了大量功能(如虛擬環境,性能分析工具等),並且可以添加各類插件,因此資源占用較多,也需要一定時間學習如何使用。
編輯頻率
根據現行方針,使用自動化工具編輯時需要注意編輯頻率,避免刷屏最近更改。
示例:使用MediaWiki api獲取用戶貢獻
雖然Pywikibot功能豐富,但有時會遇到以下情景
- 需要的功能Pywikibot無法提供
- Pywikibot提供的功能過於複雜。例如,它常常會向網站發送請求確認使用者有編輯權限,但是對於知道自己已經登錄並且有編輯權限的用戶,這一步就是多餘的。
如何使用MediaWiki api
此時可以使用MediaWiki自帶的api操作。幫助頁面給出了可用的api列表。雖然直接使用MediaWiki api花費的時間更多且更容易出錯,但是用戶可以最大程度地控制程序的行為。
以獲取用戶的所有貢獻,並分析不同名字空間的編輯次數為例。
首先前往幫助頁面查找需要的功能。用戶貢獻在query操作的usercontribs列表中。
幫助頁面給出的例子是「[1]」,該頁面列舉了User:Example的最近10條貢獻。但是,為了統計用戶所有編輯的名字空間,有以下幾個問題需要解決。
- 用戶名不一定是Example。這點很好解決,將
ucuser參數的值改為目標用戶的用戶名即可。 - 需要獲取一個用戶的所有貢獻,而不僅僅是最近的10個。解決方法是使用
continue參數中的uccontinue,向服務器發送第二個請求,要求服務器從上一次中斷的地方繼續列舉用戶的貢獻。具體用法見下文的代碼。 - 雖然有辦法獲取所有貢獻,但是一次只能獲取10個效率太低。由幫助頁面可知,可以將
uclimit參數改為500(非機器使用者的上限),一次獲取500個貢獻。 - api返回的信息包含每一次編輯的用戶名、用戶id、頁面id、編輯id、頁面名字空間、頁面標題、編輯時間和編輯摘要等內容。但是程序只需要頁面的名字空間,其它信息都是多餘的。因此,可以使用ucprop參數指定返回的信息束。ucprop的參數之一
title的描述是「添加頁面標題及其名字空間ID」,因此只需要title即可。 - api返回的是HTML頁面。雖然可讀性很高,但很難被程序處理。程序只需要json數據,因此需要加上
format=json讓api返回純json數據。
綜上所述,請求的鏈接應為「[2]」。將鏈接中的Example替換為目標用戶名就可以獲取用戶的貢獻。
使用Python獲取最近500次貢獻
第一次嘗試如下:
import requests
import json
import urllib
# 向萌百的服务器发送请求,这里以U:Lihaohong为例。为了保证可读性,代码被分成了好几行。
result = requests.get("https://zh.moegirl.org.cn/api.php?"
"action=query&list=usercontribs&"
# 注意:在url中输入非拉丁字母和非数字的字符需要用urllib.parse.quote额外处理
"ucuser=" + urllib.parse.quote("Lihaohong") + "&"
"uclimit=500&"
"ucprop=title&"
"format=json")
# 将返回的结果转化为json数据
data = json.loads(result.text)
# 输出结果
print(data)
輸出的json數據如下
{
'batchcomplete': '',
'continue': {
# 这里的数值可以用来发送下一次请求获取“下一页”贡献。
'uccontinue': '20220415095523|5841956',
'continue': '-||'
},
'query': {
'usercontribs': [
{
'userid': 741745,
'user': 'Lihaohong',
'ns': 12,
'title': 'Help:沙盒'
},
{
'userid': 741745,
'user': 'Lihaohong',
'ns': 0,
'title': '夜颜的告白'
},
{
'userid': 741745,
'user': 'Lihaohong',
'ns': 0,
'title': '最强Tettoteto计划'
},
{
'userid': 741745,
'user': 'Lihaohong',
'ns': 0,
'title': '追悔'
}
# 后面还有很多...但是总共只有500条。
]
}
}
顯然,query中的usercontribs數組存儲了用戶的編輯,其中的ns包含每次編輯的名字空間信息。
使用Python獲取所有貢獻
在統計名字空間之前,需要先使用uccontinue參數獲取用戶的全部貢獻,而不僅僅是前500個。
import requests
import json
# 用列表(数组)存储所有贡献
contributions = []
# 一开始,不需要uccontinue参数
cont = ""
while True:
# 将uccontinue参数加入请求。注意:一开始cont为空字符串。
result = requests.get("https://zh.moegirl.org.cn/api.php?"
"action=query&list=usercontribs&"
"ucuser=Lihaohong&"
"uclimit=500&"
"ucprop=title&"
"format=json" +
cont)
# 将返回的结果转化为json数据
data = json.loads(result.text)
# 提取贡献,并把贡献存入contributions
contributions.extend(data['query']['usercontribs'])
# 如果api返回的数据中包含continue,表明还有更多贡献未获取
if 'continue' in data:
# 将uccontinue参数放入cont变量,用于下一次循环的get请求
cont = "&uccontinue=" + data['continue']['uccontinue']
else: # 如果不包含continue,说明所有贡献已被读取完毕,可以退出循环
break
# 输出所有贡献
print(contributions)
# 确保贡献数正确
print(len(contributions))
運行後發現,貢獻數與用戶的真實貢獻數相同[注 7]。
使用Python分析數據
接下來,只要統計每個名字空間出現多少次即可。Python的Counter類可以快速統計數組中的每個數字出現了多少次。除此之外,還可以使用字典將數字轉換為文字。
from collections import Counter
namespace_dict = {
0: "主", 1: "讨论",
2: "用户", 3: "用户讨论",
4: "萌娘百科", 5: "萌百讨论",
6: "文件", 7: "文件讨论",
8: "MW", 9: "MW讨论",
10: "模板", 11: "模板讨论",
12: "帮助", 13: "帮助讨论",
14: "分类", 15: "分类讨论",
274: "小部件", 275: "小部件讨论",
828: "模块", 829: "模块讨论"
}
# 这里省略了之前获取contributions列表的代码
# 获取每次编辑的名字空间,并将其转换为文字(如果namespace_dict没有对应的文字,则保留数字)。最后用Counter统计每个名字空间出现了多少次。
counter = Counter([namespace_dict.get(c['ns'], c['ns'])
for c in contributions])
# 按照编辑次数给所有名字空间排序
t = sorted(list(counter.items()), key=lambda p: p[1], reverse=True)
print(t)
用戶Lihaohong的輸出為
[('主', 1253), ('用户', 279), ('帮助', 19), ('用户讨论', 16), ('萌娘百科讨论', 12), ('讨论', 10), ('模板', 9), ('模板讨论', 2), ('萌娘百科', 1)]
繪製圖表
最後,熟悉Python繪製圖表工具,例如matplotlib的用戶,可以繪製貢獻的餅狀圖和柱狀圖。
import matplotlib
import matplotlib.pyplot as plt
# 部分操作系统中,matplotlib的默认字体不支持中文,因此需要手动指定字体。
matplotlib.rcParams['font.family'] = "Heiti TC"
matplotlib.rcParams['axes.unicode_minus'] = False
# 把名字空间和编辑次数放入两个不同的列表。
namespaces, edits = zip(*t)
# 第一张图:饼状图
plt.figure(1, [10, 6])
patches, texts = plt.pie(edits, labels=namespaces)
plt.legend(patches, [f"{p[0]}: {p[1]}" for p in t],
loc='center right', bbox_to_anchor=(0, 0.5), fontsize=15)
plt.savefig("pie.png")
plt.show()
# 第二张图:柱状图
plt.figure(2, [len(namespaces), 6])
bar_plot = plt.bar(namespaces, edits, color=[p.get_facecolor() for p in patches])
plt.bar_label(bar_plot)
plt.savefig("bar.png")
plt.show()
應對WAF
對於大多數用戶,本工具已經夠用了。但是查詢編輯量極大的用戶的所有編輯需要大量(超過100個)請求,極有可能被WAF。解決方法如下:
- 使用
sleep函數,每發送一個請求就休眠數秒,減少被WAF的可能性。 - 使用
mzh域名。雖然很少被WAF,但是會被502。 - 如果被WAF,保存已有進度。下次啟動程序時從已有進度開始繼續發送請求。
以下是使用mzh域名的例子:
# 仅展示如何获取单页数据
# 循环,直到成功获取数据
while True:
try:
result = requests.get("https://mzh.moegirl.org.cn/api.php?"
"action=query&list=usercontribs&"
"ucuser=" + urllib.parse.quote("Lihaohong") + "&"
"uclimit=500&"
"ucprop=title&"
"format=json" +
cont)
# 将返回的结果转化为json数据
data = json.loads(result.text)
# 如果成功获取数据,退出循环
break
except Exception as e: # 如有Exception,多半是502了
# 输出错误信息,并重试
print(str(e), "retrying...")
最終效果
查詢萌百某用戶的編輯記錄。在發送上百個請求後,得到以下結果。
[('主', 33674), ('萌百讨论', 5931), ('模板', 5783), ('分类', 4007), ('用户', 3877), ('MW', 2887), ('用户讨论', 2365), ('萌娘百科', 862), ('讨论', 794), ('帮助', 450), ('模板讨论', 404), ('模块', 119), ('MW讨论', 102), ('小部件', 72), ('分类讨论', 17), ('帮助讨论', 9), ('小部件讨论', 7), ('模块讨论', 5)]
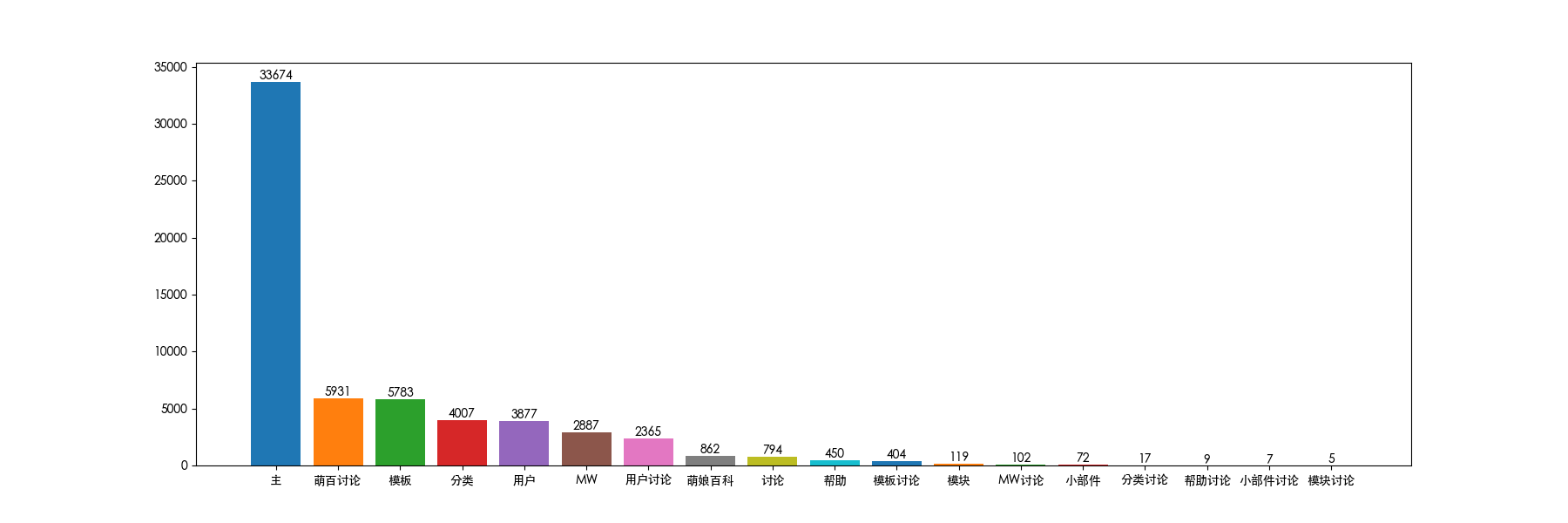
用戶貢獻柱狀圖
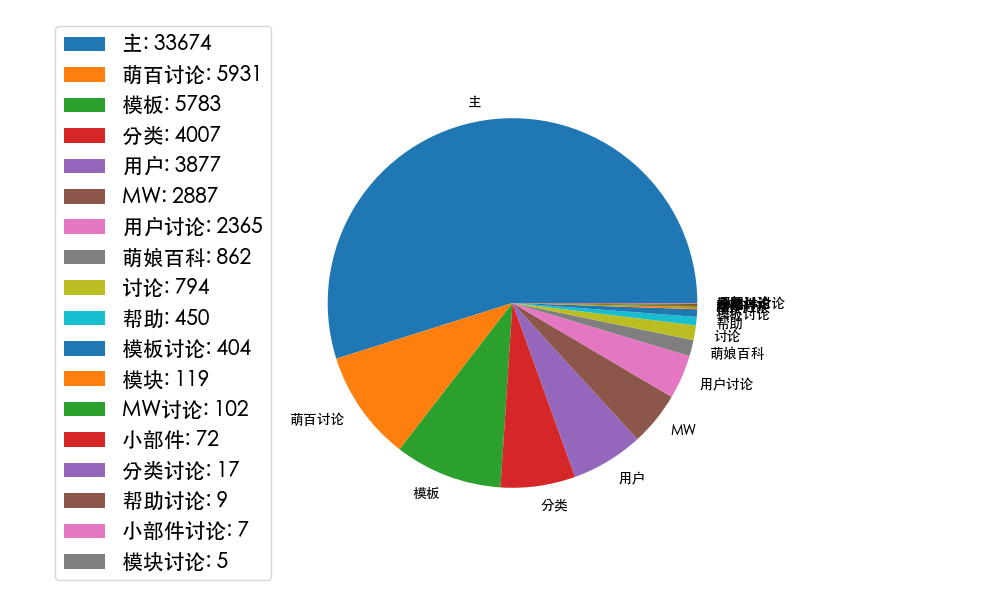
用戶貢獻餅圖

示例:使用API獲取VOCALOID歌曲條目及其重新導向信息
當你爆肝殿堂曲列表時,常常需要在萌百站內搜索殿堂列表中的曲目日文標題,以確保列表中的內鏈能正確地指向歌曲條目。
這時,你發現有億些歌曲在站內有條目,卻沒有建立原名重新導向,以致血壓升高。於是你打算整理出站內所有日文VOCALOID曲目的重新導向信息,以備篩查。
查詢query操作文檔後,發現可以通過list=search和搜索代碼獲取位於Cat:使用VOCALOID的歌曲和Cat:日本音樂作品分類中的條目、通過prop=redirects獲取至某條目的重新導向頁面列表。
| 代碼(僅作示例 |
|---|
import requests
import json
song_type = "VOCALOID"
def get_pages(offset: int):
# search通过偏移值来获取更多数据,因此这里不再使用API返回的continue数据
return json.loads(requests.get("https://zh.moegirl.org.cn/api.php", params={
"action": "query",
"list": "search",
"srsearch": f"incategory:使用{song_type}的歌曲 incategory:日本音乐作品",
"srlimit": 500,
"sroffset": offset,
"continue": "-||",
"format": "json"}).text)['query']
# titles参数长度限制为50,需切块处理
def get_redirects(pages: list[str]) -> requests.Response:
return (json.loads(requests.get("https://zh.moegirl.org.cn/api.php", params={
"action": "query",
"prop": "redirects",
"titles": '|'.join(pages),
"rdlimit": 500,
"format": "json"}).text))['query']
def get_all_redirects(pages: list[str]) -> requests.Response:
result = {'pages': {}}
for i in range(0, len(pages), 50):
result['pages'].update(get_redirects(pages[i:i+50])['pages'])
return result
data = get_pages(0)
total_count = data['searchinfo']['totalhits']
pages = {x['pageid']: x for x in data['search']}
datar = get_all_redirects([x['title'] for x in data['search']])['pages']
for k, v in datar.items():
if 'redirects' in v:
pages[int(k)]['redirects'] = v['redirects']
for i in range(500, total_count, 500):
data = get_pages(i)['search']
pages.update({x['pageid']: x for x in data['search']})
# 同上,不写了
with open("output.json", 'w', encoding='UTF-8') as f:
json.dump(pages, f, indent=4, ensure_ascii=False)
|
然而,如果直接這樣操作,不僅代碼繁瑣,還意味着每次查詢都需要向服務器多發送10次prop=redirects請求,大大增加了耗費時間、服務器負擔和WAF風險。
於是,我們可以使用生成器,在一次查詢中同時獲取頁面列表和重新導向信息。
在查詢中使用生成器(Generator)
除有特殊聲明外,query操作的絕大多數子模塊都能被用作生成器。因此,絕大多數情況下,只需將list/prop=...參數改為generator=...,其他相關參數前加上g,就能將一個普通查詢操作轉換成一個generator查詢操作。
對於一個generator查詢操作,可附加一個參數prop=A|B|C|...。這時,服務器返回的數據中,每個通過generator查詢到的頁面後都會附上指定的屬性信息,從而避免了多次發送查詢請求。
- 代碼
import requests
import json
song_type = "VOCALOID"
def get_pages_with_redirects(offset: int):
# search通过偏移值来获取更多数据,因此这里不再使用API返回的continue数据
# generator的limit值和各个prop的limit值是分别计算的
# 由于查询中重定向总数可能多于页面总数,为避免一次请求无法返回所有重定向信息,将srlimit缩减为400
return json.loads(requests.get("https://zh.moegirl.org.cn/api.php", params={
"action": "query",
"generator": "search",
"gsrsearch": f"incategory:使用{song_type}的歌曲 incategory:日本音乐作品",
"gsrlimit": 400,
"gsroffset": offset,
"continue": "gsroffset||",
"prop": "redirects",
"rdlimit": 500,
"format": "json"}).text)
pages = {}
i = 0
while True:
data = get_pages_with_redirects(i)
pages.update(data['query']['pages'])
i += 400
if not 'continue' in data: break
with open("output.json", 'w', encoding='UTF-8') as f:
json.dump(pages, f, indent=4, ensure_ascii=False)
- 程序輸出
{
"103030": {
"pageid": 103030,
"ns": 0,
"title": "1 2 fan club",
"index": 215,
"redirects": [
{
"pageid": 119944,
"ns": 0,
"title": "12 Fan Club"
},
{
"pageid": 262220,
"ns": 0,
"title": "いーあるふぁんくらぶ"
},
{
"pageid": 262222,
"ns": 0,
"title": "一二粉丝俱乐部"
}
]
},
"468148": {
"pageid": 468148,
"ns": 0,
"title": "3分钟女孩",
"index": 234,
"redirects": [
{
"pageid": 468195,
"ns": 0,
"title": "3分ガール"
},
{
"pageid": 468196,
"ns": 0,
"title": "三分钟女孩"
}
]
},
"303078": {
"pageid": 303078,
"ns": 0,
"title": "8.32",
"index": 102
},
...
}
注釋
- ↑ Windows系統下可以使用cmd或PowerShell;macOS系統下使用終端(即Terminal)即可
- ↑ 創建任何文件時請確保文件使用utf-8編碼。例如,Windows下的記事本會在保存時允許用戶選擇文件編碼。如果默認的編碼是ANSI,請把它改成utf-8。
- ↑ 以下默認使用python3。如果設備中python3命令不存在,請使用python命令。
- ↑ 如果顯示SiteDefinitionError,有可能是WAF導致的,可以在
config.py的family_files處,把https://zh.moegirl...改為https://mzh.moegirl... - ↑ 本故事純屬虛構
因為刪除參數這種事情可以直接用正則完成,根本沒有必要手動做 - ↑ 來自條目雨聲殘響的歷史版本
- ↑ 這裡的統計方式和{{User Infobox}}相同,但是與顯示貢獻數的小工具不同
參見
- Pywikibot官方教程
- wikitextparser官方文檔
- MediaWiki Action API文檔(版本較新,其中適用於本站的參數見Special:ApiHelp)
| |||||||||||||||||||||||||||||||||||